

O UiPath Document Understanding combina a RPA e a inteligência artificial para ajudá-lo a extrair e interpretar dados de diferentes documentos e garantir seu processamento de ponta a ponta. A ferramenta funciona com uma ampla variedade de documentos, desde arquivos estruturados a não estruturados e reconhece objetos diferentes como tabelas, caligrafias, assinaturas, ou caixas de seleção.
Benefícios
- Processamento de documentos rápido, preciso e flexível.
- Construído para processar vários tipos de documentos
- Sua precisão aumenta com o tempo
- Soluções de IA fora da caixa
- Automação de ponta a ponta de processos complexos
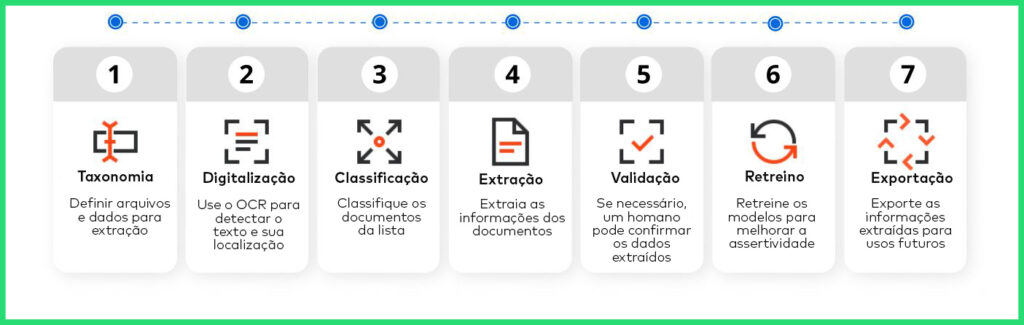
Entenda como funciona o Document Understanding
Recursos incluídos no Document Understanding
Estrutura de compreensão de documentos compostos
O Document Understanding fornece uma estrutura que pode ser composta de atividades de arrastar e soltar usadas para construir fluxos de trabalho no Studio. Desta forma, a plataforma UiPath RPA permite automação de processos mais complexos e cognitivos envolvendo grandes volumes de documentos. Além dos recursos nativos, você pode trazer seus próprios modelos ou incorporar soluções de parceiros líderes que estendem a estrutura para diversos tipos de documentos e necessidades de negócios.
Extração de dados
Extratores baseados em regras, âncoras e em modelos inteligentes lidam perfeitamente con documentos de estrutura fixa como tabelas, caligrafias, assinaturas e caixas de seleção. Assim, modelos de machine learning pré-treinados podem processar documentos menos estruturados com o mínimo tempo de configuração. Dessa forma, você pode combinar qualquer extrator em uma abordagem híbrida para garantir a mais alta precisão para o seu negócio.
Validação humana
No caso de quaisquer imprecisões, baixa confiança em pontuações ou exceções, os robôs pedem ajuda para confirmar os dados. Ou seja, um funcionário recebe uma notificação e abre a Estação de Validação ou Estação de Classificação para validar dados e tratar exceções nos resultados de extração ou classificação. Aqui você pode também revisar todos os campos extraídos, se necessário certifique-se de que os dados são processados com precisão.
Capacidades de reciclagem
Você pode rotular documentos no Data Manager e retreinar modelos de ML no AI Center para ajudar os robôs a compreender as especificidades dos seus documentos. Da mesma forma, os modelos podem ser treinados novamente – automaticamente – com base na entrada humana nas estações de validação e classificação. Este significa que quanto mais você trabalha com o modelo, mais eficaz se torna. Assim, a precisão da saída melhora com o tempo.
O Document Understaning é um dos pilares da Hiperautomação.
Saiba mais em: Hiperautomação gera empresas totalmente automatizadas
Veja nossos vídeos sobre DU em nosso canal do YouTube: